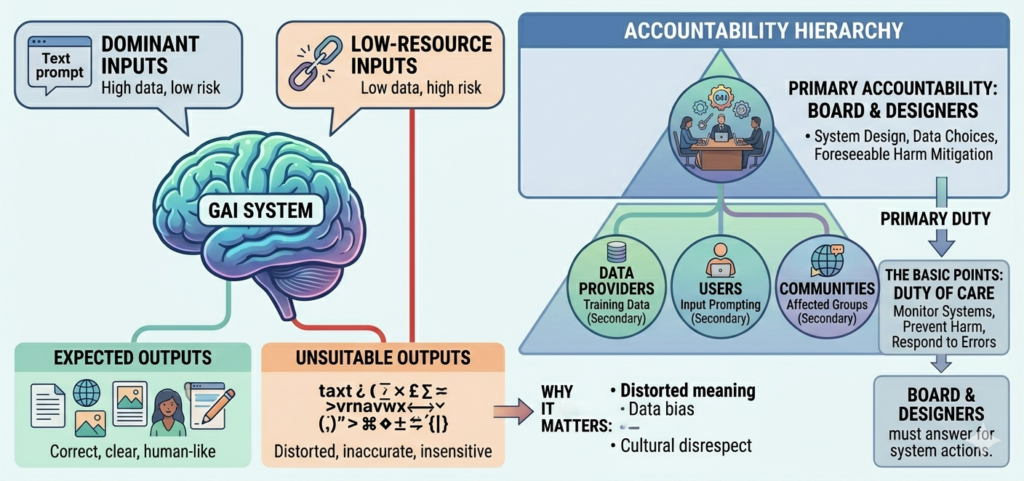
Low-resource language communities themselves should not be burdened with the primary obligation to correct harms arising, and imposed on them, from GAI systems.
Generative artificial intelligence (GAI) is a form of artificial intelligence that can create new content, such as text, designs, images, video and music, by learning patterns from existing data. In the context of creative industries, GAI can be used to generate innovative or transformative content based on input prompts. These systems can produce outputs that resemble human-created content. This is a significant addition to how content and works used in creative industries or individual pursuits are conceived, produced and distributed. To understand responsibility for a GAI system, one has to examine certain background matters, in this case in relation to GAI and textual languages.
Language use in GAI
The range of textual content GAI can produce is, however, dependent on the languages used in its training data and as input prompts, which in turn reflect cultural and linguistic structures embedded within those languages (Lu, Song & Zhang, 2025). Culture can be considered as a shared system of meanings, values, traditions and practices through which a community understands and communicates its identity and worldview. It encompasses not only creative expressions, but also social norms, knowledge systems, and ways of interpreting reality. Language is critical to cultural expression because it carries cultural knowledge, metaphors, histories and ways of thinking that cannot always be directly translated into other languages without loss of meaning.
Languages have varying resource bases, that is, material or fixed expressions and demographic support, that they can draw from. This is due to historical, political, economic, technological and population factors that influence how much a language is used, recorded, digitised and institutionally supported, and of course taught. These factors also shape how ideas are framed, how stories are told, and how cultural identity is maintained and transmitted across generations.
Low-resource and high-resource/dominant languages
Some languages have vast corpora of books, media, websites and formal documentation. These are dominant or high-resource languages, which are often well represented in digital platforms, software systems, and GAI training datasets, as well as in science, commerce and media generally. Examples include English, Mandarin Chinese, Spanish and French, which have strong institutional support. These languages benefit from continuous reinforcement through global communication, publishing and technological integration.
Other less-used languages have limited written records, fewer digitised expressions and minimal representation in online or machine-readable formats, as well as minimal institutional support by the state. Sometimes it is left to tribal structures or civil society organisations to keep these languages alive. These are low-resource languages. (HAI, 2025)
Characteristics of a low-resource language include small corpora of digitised text, limited online presence, fewer speakers relative to a dominant language, lack of standardised writing system in some cases, and minimal representation in GAI training datasets. They are often found in indigenous or traditional communities, minority populations and developing regions, where oral tradition may be stronger than written documentation and where technological and institutional support has historically been limited. Accordingly, there is limited general application of data from low-resource languages for educational, technological or computational use, particularly in digital formats, though they are of specific interest to researchers.
Inputs and outputs
To produce outputs from a GAI system requires inputs. One major input is text prompts, typically written in a dominant language such as English, inserted into a prompt dialog box of a computing device. These prompts provide instructions, context and constraints that guide the system’s response. The system processes the text prompt by converting it into numerical representations of linguistic syntax, vocabulary and semantic meaning, which are compared against patterns learned during training from vast datasets of existing text. Based on these learned statistical relationships, the system generates output that reflects the most probable response consistent with the prompt and the system’s training data.
Given that GAI systems are trained largely on dominant languages (Goodwin-Jones, 2024), especially English, the internal representations of these languages are far richer and more precise. This enables the system to interpret context, idiomatic expressions and ambiguity more effectively in dominant languages than in low-resource languages. This means a GAI system’s accuracy and reliability are closely tied to the quantity, quality and diversity of linguistic data available to it from a language.
All languages have their irregularities, ambiguities and contextual dependencies, which can be considered imperfections from a computational perspective. For dominant languages, these imperfections are often absorbed into the training process (Cao et al, 2023) because the sheer volume of available data allows a GAI system to learn exceptions, idioms, dialectal variations and contextual subtleties. As a result, errors in dominant languages tend to appear as technical glitches rather than systemic failures. The abundance of data allows a system to approximate correct usage even in complex situations.
Unsuitable outputs
Low-resource languages, by contrast, have more limited representation in training datasets. When used in a GAI system, prompts tend to be processed with lower accuracy, weaker contextual understanding, and greater reliance on approximation. The system likely struggles with syntax, vocabulary and culturally specific references because it has encountered fewer examples during training. In some cases, the system may default to patterns learned from dominant languages, effectively translating concepts from low-resource languages incorrectly, oversimplifying meaning, or producing hybrid outputs that reflect structural bias toward a dominant language (Jeon et al, 2025). The system may also fail to recognise culturally specific concepts that do not have direct equivalents in a dominant language.
Consequently, inaccurate, deficient, inappropriate or culturally insensitive outputs (‘unsuitable outputs’) can be produced. Meaning may be distorted, nuance lost, or culturally important distinctions erased. This is due to lack of sufficient linguistic training from datasets. Furthermore, users of low-resource languages tend to receive lower-quality GAI assistance. This is a form of technological inequality.
Question of responsibility
The question of responsibility for unsuitable outputs appears unavoidable. Developers (including designers), dataset providers, deployers, users and other beneficiaries, as well as language communities as a whole, are all involved or affected. The unsuitable outputs are not merely technical defects, but can involve matters that touch on dignity, cultural integrity, ethics and equitable distribution of technological risk.
The answer is layered, but primary responsibility should rest with developers and deployers of GAI systems. This is because they design the system, choose the training data sources, determine training parameters, and control release conditions (Taeihagh, 2025). They occupy the position of foreseeable risk creators, so are best placed to anticipate, mitigate and prevent unsuitable outputs, and in particular any harms, before they occur. In ethical terms, they shape the architecture that governs use of a system at scale. That architecture influences how language is used and processed across millions of interactions.
Others such as dataset providers, users and language communities are secondary. In this regard, dataset providers may be internal to developers and deployers or under contract to them, so act according to their employment or contractual obligations. All such persons are more remote from decisions on development and deployment, but ethically could also bear some responsibility, e.g. for poor input or use decisions. One cannot rule out entirely that they may contribute to unsuitable outputs.
This tiering recognises that developers and deployers do not operate in isolation. GAI technologies in the creative space do function as co-creative tools. Yet those that are secondary to primary development and deployment cannot reasonably be expected to audit linguistic accuracy or check cultural protocols that should, at least ethically, be considered at the design stage (Brey & Dainow, 2024). This is a critical stage in setting parameters regarding future use. So, if a system is trained on mislabelled or scraped internet data and later produces unsuitable outputs, that is not a neutral accident. It reflects design decisions and failure to take responsibility for poor decisions. That decision-making really vests in the board of directors at the top of a GAI enterprise, who should act diligently and carefully (Tiano et al, 2024). They should assess foreseeable harm before implementation.
Conclusion
In the end, responsibility follows agency. Those who design, develop and deploy GAI systems at scale must shoulder primary corrective duty. They have responsibilities and obligations to monitor system implementation and possible unsuitable outputs, implement safeguards, and respond to complaints. They shape human‑centred GAI experiences, so should be advocating for ethical outcomes, inclusion of users and their needs (which will likely maximise market value), and human rights. They are also the only ones who can make ongoing corrections. Practically, anyone else acting reasonably and exercising critical judgement is only likely to have some lesser secondary responsibility.
Additionally, the human power behind a GAI system lies in those who govern it, ultimately the board of directors of the enterprise. So, they have to answer for what goes wrong, and correct harms. Otherwise, innovation without accountability is unfair profit extraction. Low-resource language communities themselves should not be burdened with the primary obligation to correct harms arising, and imposed on them, from GAI systems. To do so would invert the ethical order, shifting the costs of harms from technological innovation onto those least resourced to bear them.
References
Brey, P. and Dainow, B. (2024) ‘Ethics by design for artificial intelligence’. AI and Ethics, 4, pp.1265–1277. Available at: https://link.springer.com/article/10.1007/s43681-023-00330-4
Cao, Y., Zhou, L., Lee, S., Cabello, L., Chen, M. and Hershcovich, D. (2023) Assessing cross-cultural alignment between ChatGPT and human societies: An empirical study. Available at: https://doi.org/10.48550/arXiv.2303.17466
Godwin‑Jones, R. (2024) Generative AI, Pragmatics, and Authenticity in Second Language Learning. Available at: https://arxiv.org/pdf/2410.14395
HAI. (2025) Mind the (Language) Gap: Mapping the Challenges of LLM Development in Low‑Resource Language Contexts. Stanford Institute for Human‑Centered Artificial Intelligence. Available at: https://hai.stanford.edu/assets/files/hai-taf-pretoria-white-paper-mind-the-language-gap.pdf
Jeon, J., Wei, L., Tai, K.W.H. and Lee, S. (2025) ‘Generative AI and its dilemmas: exploring AI from a translanguaging perspective’. Applied Linguistics, 46(4), 709-717. Available at: https://www.researchgate.net/publication/394128596_Generative_AI_and_its_dilemmas_Exploring_AI_from_a_translanguaging_perspective
Lu, J.G., Song, L.L. and Zhang, L.D. (2025) ‘Cultural tendencies in generative AI’, Nature Human Behaviour, 9, 2360-2369. Available at: https://doi.org/10.1038/s41562-025-02242-1
Taeihagh, A. (2025) ‘Governance of Generative AI’. Policy and Society, 44(1), 1-22. Available at: https://doi.org/10.1093/polsoc/puaf001
Tiano Jr., J.R., Rapoport, N.B., Wilson, J. and Aquino, S.R. (2024) The duty of supervision in the age of generative AI: urgent mandates for a public company’s board of directors and its executive and legal team, Business Law Today (American Bar Association). Available at: https://www.americanbar.org/groups/business_law/resources/business-law-today/2024-march/the-duty-of-supervision-in-the-age-of-generative-ai/
https://open.substack.com/pub/macropsychic/p/responsibility-in-generative-ai-for