There is no copying – there is only transformative use
What people get wrong about so-called ‘copying’ of training data for generative artificial intelligence (GAI). There is no copying! Text used in training is not stored inside the model as paragraphs or documents!
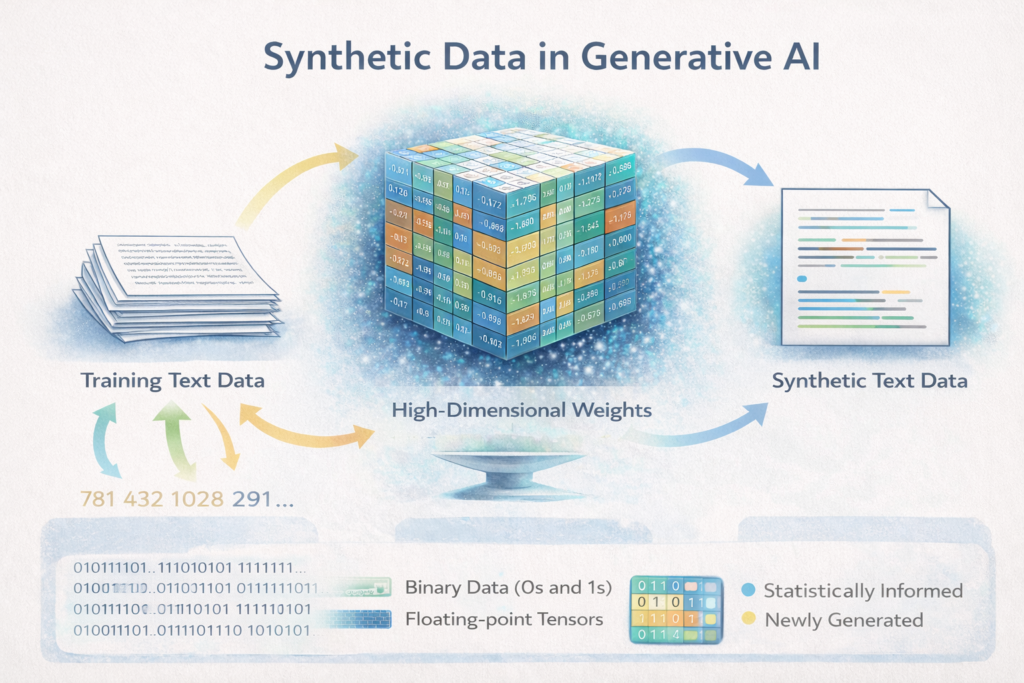
At the lowest physical level, everything in a computer, including training data, model weights and synthetic data, is represented as 0s and 1s. Even so, that is not the level at which generative AI actually ‘understands’ or processes text. What then is the understanding?
When text is used in training, it is not stored inside the model as paragraphs or documents. Instead, it is converted into numerical representations called tokens, and those tokens are mapped into high-dimensional vectors (arrays of numbers). The model then adjusts billions of internal parameters (weights) so that it becomes very good at predicting the next token given context. What remains after training is not text. Rather, it is a large matrix of numerical weights that encode statistical relationships between patterns of language.
What does synthetic data look like?
Synthetic data in AI does not mean text turned into a different digital file format. It means newly generated data created by a model that has learned statistical patterns from real data. For text models:
- The model generates new token sequences.
- These tokens are converted back into readable text.
- That text did not exist previously as a stored document.
- It is produced by probabilistic prediction, not copying.
Internally, synthetic data looks like:
- A sequence of token IDs (integers).
- Each token is represented as a vector (lists of floating-point numbers).
- Ultimately encoded as binary in memory.
But conceptually, synthetic data looks like ordinary text when rendered, i.e. as paragraphs, sentences, code, because the numerical predictions are mapped back into human-readable symbols. Importantly:
- The model does not retain a database of training documents.
- It does not transform original text into “encrypted variants”.
- It stores parameterised probability distributions over token sequences.
You can think of it like this:
training text → converted into patterns of statistical relationships → compressed into numerical weights → used to generate new sequences that fit those patterns.
The synthetic output is therefore:
- Statistically informed by training data.
- But not a transformed version of any particular document.
- And not stored as a re-labelled copy.
A useful analogy is learning grammar and style. A human who reads thousands of legal contracts does not store each contract verbatim (normally). Instead, they internalise structural patterns and can draft a new contract that resembles prior ones without copying them. The model operates similarly, except mathematically.
So, what does synthetic data “look like”?
At the machine level: Floating-point tensors (multi-dimensional arrays of numbers).
- At the storage level: Binary data (0s and 1s).
- At the human level: Newly generated text, images, code, etc, assembled from learned probability patterns.
- It is neither stored original text nor encrypted derivatives — it is probabilistic reconstruction based on learned structure.
It is transformative!
https://substack.com/@macropsychic/note/c-222331600